Heart Internet :: wp_options table creates lots of transient records
One of my clients received an email from Heart Internet recently stating that a database on their account had exceeded limit of 500MB and had ballooned to 3,561MB. This was a bit of a shock as the database holds a WordPress install which only has 82 posts.
My initial thought was that the comments hadn't been disabled and were most likely filling up the database, but when I checked phpMyAdmin I found that everything appeared to reasonably small in table size except for `wp_options` which although only had 370 records was somehow using up 3.4GB by itself.
When I looked into the table I found the usual `transient` records at the end of the table, these look to be temporary records with a short ttl. So the space which is being used appears to be overhead, although it doesn't show as such. But rebuilding the table via `OPTIMIZE TABLE` brings down the table size to a mere 1.5MB.
As this was the second time this client got an email from Heart with this issue I put together a scheduled task which optimises the `wp_options` table each day. Hopefully this will be useful for you.
I placed the scheduled task file above the `public_html` folder, within a folder called `crons` and called the file `optimise-db.php`. You can change the location and name of the file but you'll need to update the paths used in the code and control panel.
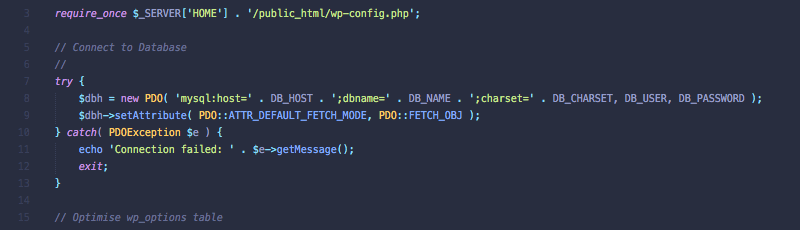
File: ~/crons/optimise-db.php
<?php
require_once $_SERVER['HOME'] . '/public_html/wp-config.php';
// Connect to Database
//
try {
$dbh = new PDO( 'mysql:host=' . DB_HOST . ';dbname=' . DB_NAME . ';charset=' . DB_CHARSET, DB_USER, DB_PASSWORD );
$dbh->setAttribute( PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_OBJ );
} catch( PDOException $e ) {
echo 'Connection failed: ' . $e->getMessage();
exit;
}
// Optimise wp_options table
//
try {
print_r( $result = $dbh->query( 'OPTIMIZE TABLE `' . $table_prefix . 'options`' )->fetch() );
} catch( PDOException $e ) {
echo 'Connection failed: ' . $e->getMessage();
exit;
}The file will use the table prefix as set within `wp-config.php` so this should be a case of just copy and paste. You can use an include file within `public_html` if you want to test this file works.
File ~/public_html/test.php
<?php require_once '../crons/optimise-db.php';
Next you'll need to add the `optimise-db.php` file to a scheduled task.
The command you use should be similar to the below but you'll need to update the path to the file.
/usr/bin/php56 -f /home/sites/example.org/crons/optimise-db.php
Here I'm using PHP 5.6 as I know Heart will continue to support this for sometime and something as simple as running a single MySQL query won't require PHP 7.
You can set the task to run once per week or once per day (usually at midnight). I opted for each midnight.
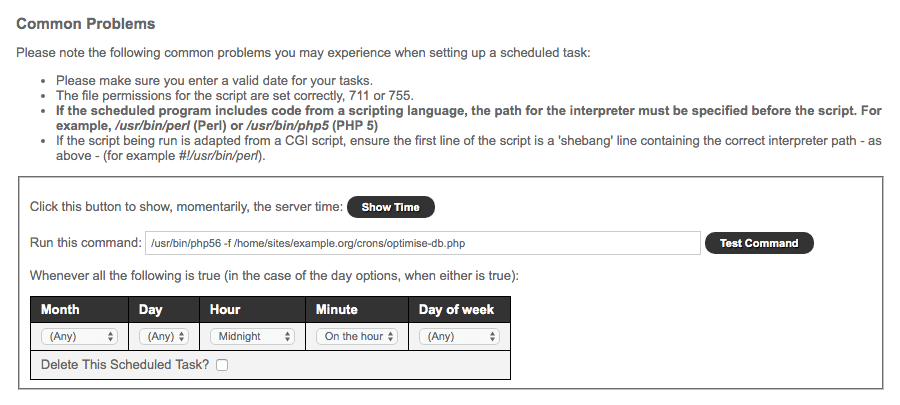
With this set, you can click on the `Test Command` button and you should receive the following output:
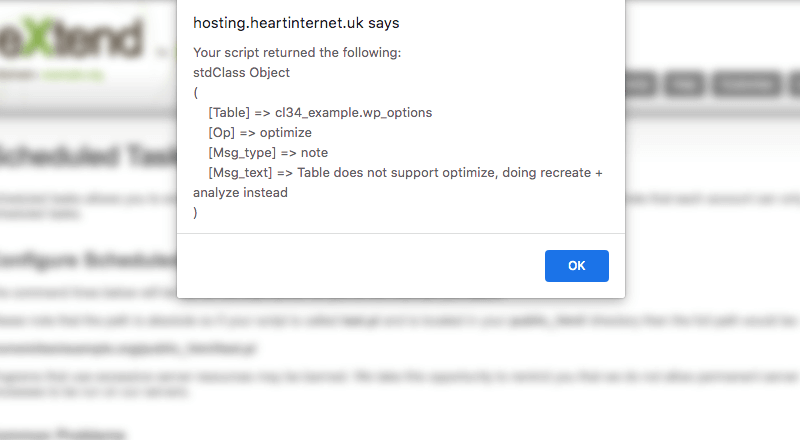
And that's it. This scheduled task will keep your transient records from filling up your database table.
If you have any questions I might be able to help, so tweet me @WilliamIsted.